We optimize for the only thing that matters: How many tasks a model solves.
We optimize for the only thing that matters: How many tasks a model solves.
We optimize for the only thing that matters: How many tasks a model solves.

We optimize for the only thing that matters: How many tasks a model solves.
Introducing Small 2.0. Our most powerful agentic model yet.

2 min read
2 min read
Copy URL
Copied
Copy URL
Copied
November 10, 2025
We spoke to our users. We listened, refined, and improved.
Small 2.0 is our largest fine-tuned model yet, built on the Minimax M2 architecture — it takes everything you loved about the original and pushes it miles further.
Sharper reasoning. Smoother execution and now, real-time understanding across your tools, files, and the web — so you can get more done without lifting a finger.
What makes Small 2.0 more Incredible
Feature | Description |
|---|---|
3× Faster Reasoning | Generates and executes responses in real time — no lag, no stalls. |
Deeper Understanding | Handles multi-step, context-heavy workflows with sharper logic and memory. |
File Uploads + Analysis | Reads, interprets, and acts on large or complex files effortlessly. |
Web Search + Live Data | Pulls real-time insights, sources, and stats directly into your workflow. |
Connected Apps | Works seamlessly across your daily stack — Notion, Sheets, Slack, Drive, and beyond. |
Benchmarks
Small 2.0 is our largest fine-tuned model yet, built on the latest Minimax M2 architecture — it takes everything you loved about the original and pushes it miles further.
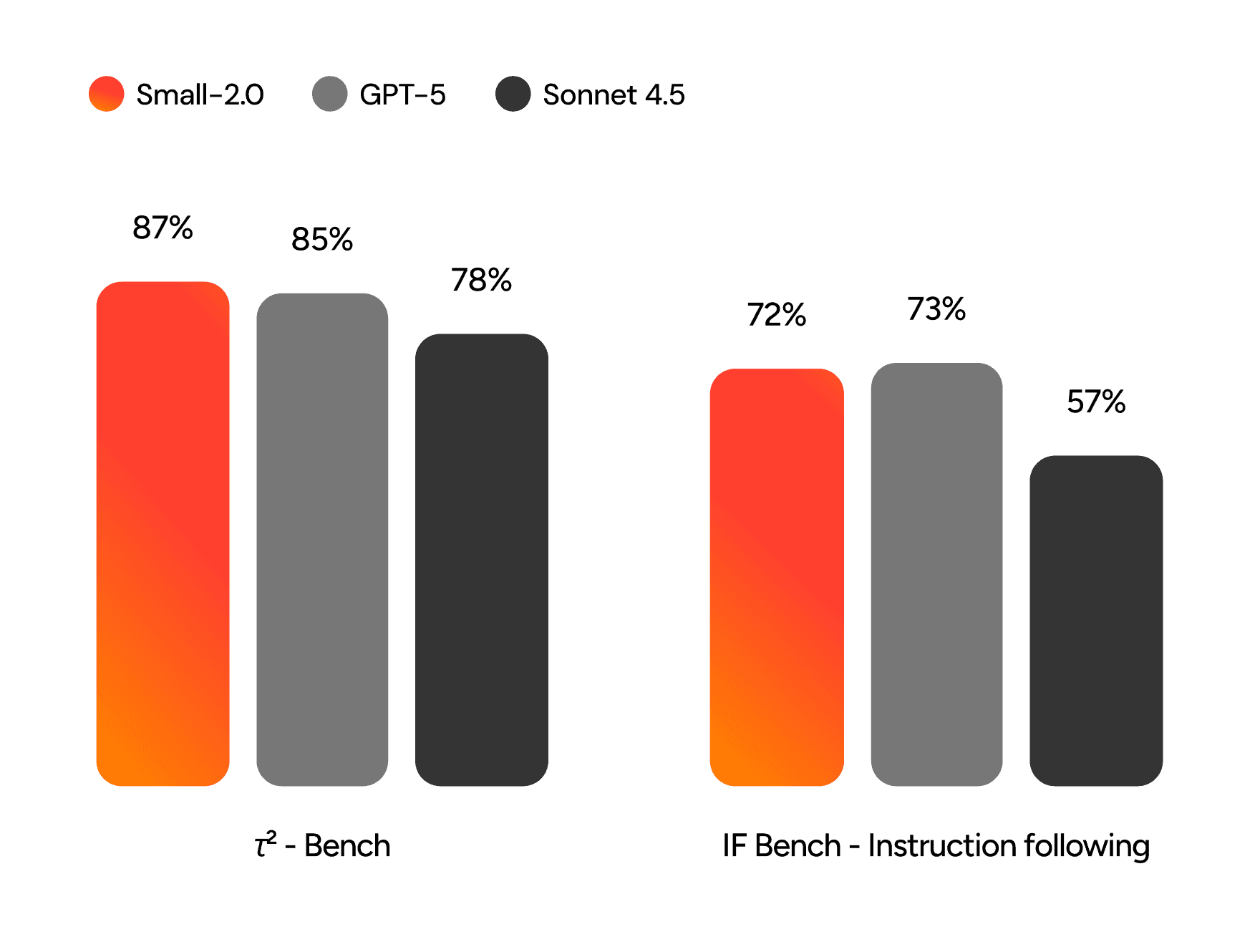
We tested Small 2.0 against GPT and Claude on the two benchmarks that actually predict whether an AI can complete real work, not just generate impressive responses. Most LLM leaderboards measure conversational ability: how well a model answers trivia or writes essays. Useful for chatbots, irrelevant for agents.
Tau Bench measures tool use: whether a model executes accurate, multi-step function calls without hallucinating parameters or breaking the chain. On the other hand, IF Eval measures instruction following: whether it actually follows all constraints you give it, not just the convenient ones.
Incredible Small 2.0 ranks superior to traditional LLMs on multi step function calls as depicted in our TAU bench results and stands pretty close to GPT-5 on the scale of following instructions.
This is remarkable that Incredible Small 2.0 ranks this high with almost 1/10 of the cost of a traditional LLM.
Ready to see it in action?
Check out Incredible Small 2.0 now on the Incredible Assistant
You can also work with the Small 2.0 model with our Incredible API. Refer docs.incredible.one. Contact our sales team to get access to the API. Drop a mail to fredric@incredible.one (API platform coming soon).
Most models just talk.
Incredible delivers — accurate, practical, and built for real workflows.
We spoke to our users. We listened, refined, and improved.
Small 2.0 is our largest fine-tuned model yet, built on the Minimax M2 architecture — it takes everything you loved about the original and pushes it miles further.
Sharper reasoning. Smoother execution and now, real-time understanding across your tools, files, and the web — so you can get more done without lifting a finger.
What makes Small 2.0 more Incredible
Feature | Description |
|---|---|
3× Faster Reasoning | Generates and executes responses in real time — no lag, no stalls. |
Deeper Understanding | Handles multi-step, context-heavy workflows with sharper logic and memory. |
File Uploads + Analysis | Reads, interprets, and acts on large or complex files effortlessly. |
Web Search + Live Data | Pulls real-time insights, sources, and stats directly into your workflow. |
Connected Apps | Works seamlessly across your daily stack — Notion, Sheets, Slack, Drive, and beyond. |
Benchmarks
Small 2.0 is our largest fine-tuned model yet, built on the latest Minimax M2 architecture — it takes everything you loved about the original and pushes it miles further.
We tested Small 2.0 against GPT and Claude on the two benchmarks that actually predict whether an AI can complete real work, not just generate impressive responses. Most LLM leaderboards measure conversational ability: how well a model answers trivia or writes essays. Useful for chatbots, irrelevant for agents.
Tau Bench measures tool use: whether a model executes accurate, multi-step function calls without hallucinating parameters or breaking the chain. On the other hand, IF Eval measures instruction following: whether it actually follows all constraints you give it, not just the convenient ones.
Incredible Small 2.0 ranks superior to traditional LLMs on multi step function calls as depicted in our TAU bench results and stands pretty close to GPT-5 on the scale of following instructions.
This is remarkable that Incredible Small 2.0 ranks this high with almost 1/10 of the cost of a traditional LLM.
Ready to see it in action?
Check out Incredible Small 2.0 now on the Incredible Assistant
You can also work with the Small 2.0 model with our Incredible API. Refer docs.incredible.one. Contact our sales team to get access to the API. Drop a mail to fredric@incredible.one (API platform coming soon).
Most models just talk.
Incredible delivers — accurate, practical, and built for real workflows.
We spoke to our users. We listened, refined, and improved.
Small 2.0 is our largest fine-tuned model yet, built on the Minimax M2 architecture — it takes everything you loved about the original and pushes it miles further.
Sharper reasoning. Smoother execution and now, real-time understanding across your tools, files, and the web — so you can get more done without lifting a finger.
What makes Small 2.0 more Incredible
Feature | Description |
|---|---|
3× Faster Reasoning | Generates and executes responses in real time — no lag, no stalls. |
Deeper Understanding | Handles multi-step, context-heavy workflows with sharper logic and memory. |
File Uploads + Analysis | Reads, interprets, and acts on large or complex files effortlessly. |
Web Search + Live Data | Pulls real-time insights, sources, and stats directly into your workflow. |
Connected Apps | Works seamlessly across your daily stack — Notion, Sheets, Slack, Drive, and beyond. |
Benchmarks
Small 2.0 is our largest fine-tuned model yet, built on the latest Minimax M2 architecture — it takes everything you loved about the original and pushes it miles further.
We tested Small 2.0 against GPT and Claude on the two benchmarks that actually predict whether an AI can complete real work, not just generate impressive responses. Most LLM leaderboards measure conversational ability: how well a model answers trivia or writes essays. Useful for chatbots, irrelevant for agents.
Tau Bench measures tool use: whether a model executes accurate, multi-step function calls without hallucinating parameters or breaking the chain. On the other hand, IF Eval measures instruction following: whether it actually follows all constraints you give it, not just the convenient ones.
Incredible Small 2.0 ranks superior to traditional LLMs on multi step function calls as depicted in our TAU bench results and stands pretty close to GPT-5 on the scale of following instructions.
This is remarkable that Incredible Small 2.0 ranks this high with almost 1/10 of the cost of a traditional LLM.
Ready to see it in action?
Check out Incredible Small 2.0 now on the Incredible Assistant
You can also work with the Small 2.0 model with our Incredible API. Refer docs.incredible.one. Contact our sales team to get access to the API. Drop a mail to fredric@incredible.one (API platform coming soon).
Most models just talk.
Incredible delivers — accurate, practical, and built for real workflows.


Incredible goes beyond conversation to become an AI agent that actually does deep work for you in the background end to end.
Incredible goes beyond conversation to become an AI agent that actually does deep work for you in the background end to end.
Incredible goes beyond conversation to become an AI agent that actually does deep work for you in the background end to end.
Incredible goes beyond conversation to become an AI agent that actually does deep work for you in the background end to end.
Incredible, all rights reserved, 2025
Incredible, all rights reserved, 2025
Incredible, all rights reserved, 2025
